Menu
Solving the Hallucination Problem: The Power of RAG and Local LLMs
Published on November 28, 2025
Solving the Hallucination Problem: The Power of RAG and Local LLMs
As AI systems become more capable, a critical concern continues to slow enterprise adoption: hallucinations. These occur when large language models generate responses that sound confident but are factually incorrect or completely fabricated.
For industries such as law, finance, healthcare, and government, even a single incorrect output can lead to serious legal, financial, or reputational consequences. In these environments, accuracy is not optional—it is mandatory.
This is where Retrieval-Augmented Generation (RAG) and local LLM deployments fundamentally change the equation.
Data Sovereignty: Keeping Control of What Matters Most
One of the core principles of enterprise AI is data sovereignty.
Organizations must know:
- Where their data is stored
- Who can access it
- How it is processed
By deploying AI systems on-premise or within private cloud environments, companies eliminate the risk of sensitive information being sent to third-party servers. Local LLMs ensure that proprietary documents, internal policies, and confidential records never leave the organization’s controlled infrastructure.
This approach is especially critical for regulated sectors that must comply with strict data protection laws and internal governance policies.
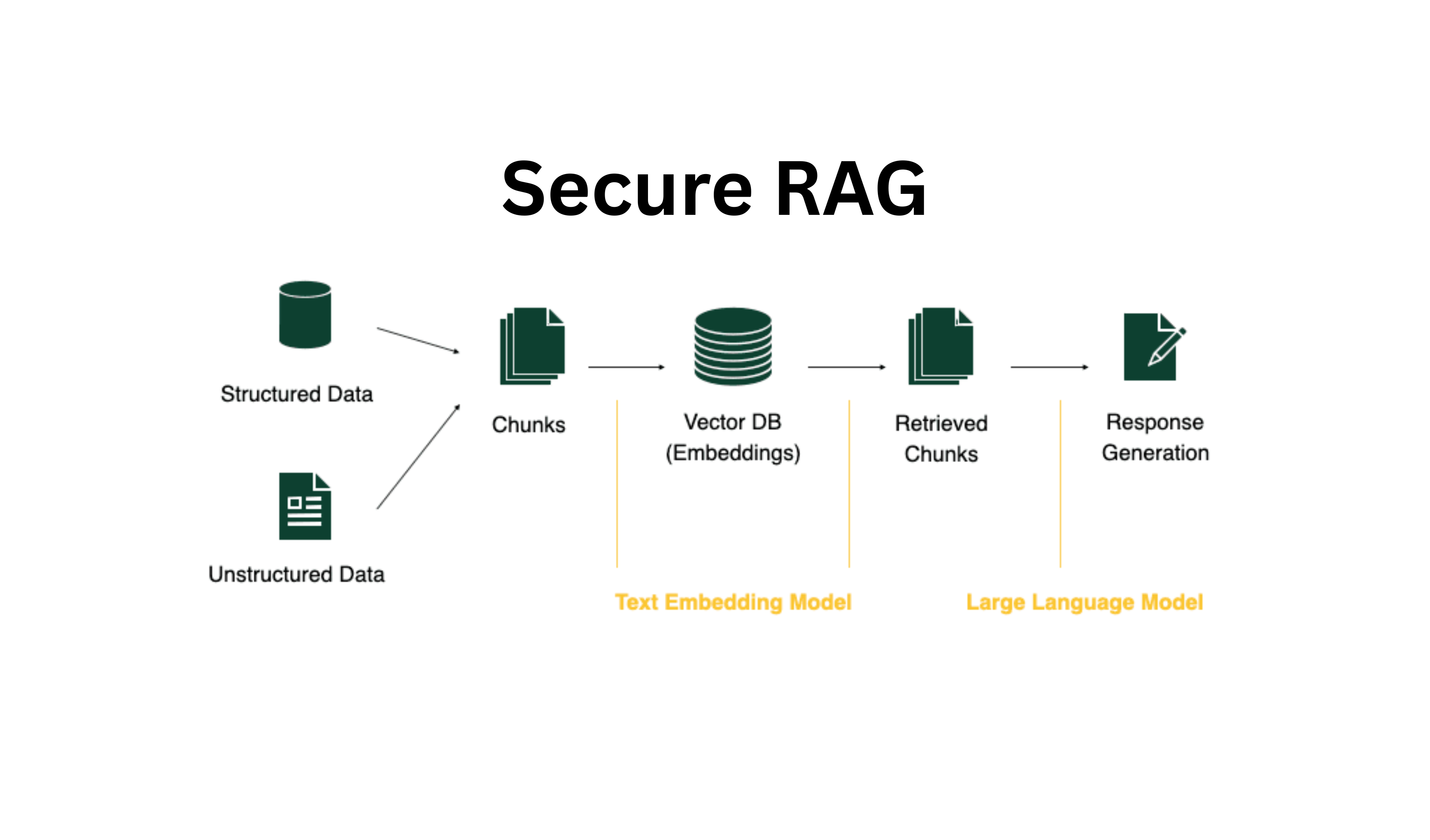
RAG Architecture: Grounding AI in Reality
Retrieval-Augmented Generation addresses hallucinations at their root cause.
Instead of relying solely on a model’s internal knowledge, RAG systems:
- Retrieve relevant information from trusted internal documents
- Inject that information directly into the model’s context
- Generate responses strictly based on retrieved sources
The result is AI output that is grounded in real, verifiable data.
If the answer does not exist in the knowledge base, the system simply does not invent one.
This architecture transforms LLMs from creative text generators into reliable enterprise knowledge workers.
Dual-Layer Verification: Trust, but Verify
At AIME, we go one step further with dual-layer verification.
In this approach:
- A primary model generates the response using RAG
- A secondary model independently validates the output
- Inconsistencies, unsupported claims, or missing references are flagged automatically
This cross-checking mechanism dramatically increases reliability and minimizes the risk of misinformation reaching end users.
The outcome is an AI system that behaves less like a chatbot—and more like a highly disciplined analyst.
Secure AI Is Not Optional
Security should never be an afterthought in AI system design.
By combining:
- Local data sources
- Isolated execution environments
- RAG-based grounding
- Multi-model verification
Businesses can confidently leverage the power of large language models without compromising data privacy or factual accuracy.
At AIME, we build AI ecosystems where security, accuracy, and trust are foundational—not optional features. This enables organizations to adopt AI at scale while meeting the highest standards of enterprise security and compliance.